
Golang的io库-Reader-writer-copy
鱼跃此时海,花开彼岸天。
IO包
Go语言的io包可以在多种类型的数据之间转化。

实际上,通过io.Reader和io.Writer接口我们可以简单地将数据源拷贝到目的。
io.Reader/Writer是比较常用的接口。很多原生的结构都围绕这个系列的接口展开,在实际的开发过程中,你会发现通过这个接口可以在多种不同的io类型之间进行过渡和转化。
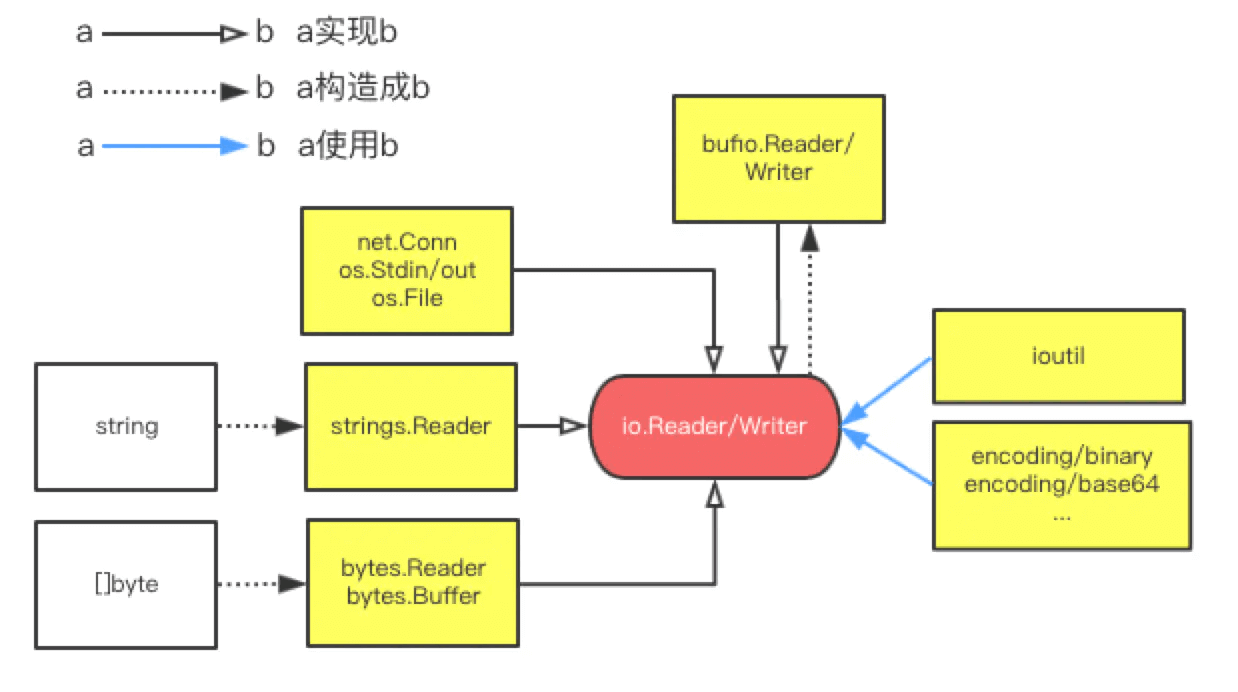
围绕io.Reader/Writer,有几个常用的实现:
net.Conn, os.Stdin, os.File: 网络、标准输入输出、文件的流读取
strings.Reader: 把字符串抽象成Reader
bytes.Reader: 把[]byte抽象成Reader
bytes.Buffer: 把[]byte抽象成Reader和Writer
bufio.Reader/Writer: 抽象成带缓冲的流读取(比如按行读写)
场景举例
base64编码成字符串
这个用来做base64编码,但是仔细观察发现,它需要一个io.Writer作为输出目标,并用返回的WriteCloser的Write方法将结果写入目标,下面是Go官方文档的例子
input := []byte("foo\x00bar")
encoder := base64.NewEncoder(base64.StdEncoding, os.Stdout)
encoder.Write(input)
这个例子是将结果写入到Stdout,如果我们希望得到一个字符串呢?观察上面的图,不然发现可以用bytes.Buffer作为目标io.Writer:
input := []byte("foo\x00bar")
buffer := new(bytes.Buffer)
encoder := base64.NewEncoder(base64.StdEncoding, buffer)
encoder.Write(input)
fmt.Println(string(buffer.Bytes())
[]byte和struct之间正反序列化
这种场景经常用在基于字节的协议上,比如有一个具有固定长度的结构:
type Protocol struct {
Version uint8
BodyLen uint16
Reserved [2]byte
Unit uint8
Value uint32
}
通过一个[]byte来反序列化得到这个Protocol,一种思路是遍历这个[]byte,然后逐一赋值。其实在encoding/binary包中有个方便的方法:
func Read(r io.Reader, order ByteOrder, data interface{}) error
这个方法从一个io.Reader中读取字节,并已order指定的端模式,来给填充data(data需要是fixed-sized的结构或者类型)。要用到这个方法首先要有一个io.Reader,从上面的图中不难发现,我们可以这么写:
var p Protocol
var bin []byte
//...
binary.Read(bytes.NewReader(bin), binary.LittleEndian, &p)
换句话说,我们将一个[]byte转成了一个io.Reader。
反过来,我们需要将Protocol序列化得到[]byte,使用encoding/binary包中有个对应的Write方法:
func Write(w io.Writer, order ByteOrder, data interface{}) error
通过将[]byte转成一个io.Writer即可:
var p Protocol
buffer := new(bytes.Buffer)
//...
binary.Writer(buffer, binary.LittleEndian, p)
bin := buffer.Bytes()
从流中按行读取
比如对于常见的基于文本行的HTTP协议的读取,我们需要将一个流按照行来读取。本质上,我们需要一个基于缓冲的读写机制(读一些到缓冲,然后遍历缓冲中我们关心的字节或字符)。在Go中有一个bufio的包可以实现带缓冲的读写:
func NewReader(rd io.Reader) *Reader
func (b *Reader) ReadString(delim byte) (string, error)
这个ReadString方法从io.Reader中读取字符串,直到delim,就返回delim和之前的字符串。如果将delim设置为\n,相当于按行来读取了:
var conn net.Conn
//...
reader := NewReader(conn)
for {
line, err := reader.ReadString([]byte('\n'))
//...
}
io.Reader
对于一个io.Reader,数据会被读取到一个缓存中,然后被其他的函数调用消费。其必须实现Read(p ] byte)方法。
type Reader interface {
Read(p []type) (n int, err error)
}
实现这个方法可以返回读取到的字节数和错误,如果数据源已经读取完成,将会返回io.EOF。
读取规则
- 只要数据足够, 读取的时候会读取输入的
len(p)长度的字节。 - 在一个
Read()调用之后,n可能会比len(p)要小。 - 及时发生错误,缓存
p中可能还是会返回n字节。 - 当一次读取完成后,可能返回一个非0的
n和err=io.EOF。然而,也可能会返回一个非零的n和err=nil,这种情况下,后续的读取必须返回n=0, err=EOF。 - 一次对于
Read()的调用返回了n=0和err=nil并不意味着结束,继续调用可能会获取到更多数据。
从字符串读取
func main() {
reader := strings.NewReader("Clear is better than clever")
p := make([]byte, 4)
for {
n, err := reader.Read(p)
if err == io.EOF {
break
}
fmt.Println(string(p[:n]))
}
}
上面的例子中,从字符串中循环读取并打印。
上面的例子有一个bug,就是不能够获取到err中发生的错误,可以修改为如下
func main() {
reader := strings.NewReader("Clear is better than clever")
p := make([]byte, 4)
for {
n, err := reader.Read(p)
if err != nil{
if err == io.EOF {
fmt.Println(string(p[:n])) //should handle any remainding bytes.
break
}
fmt.Println(err)
os.Exit(1)
}
fmt.Println(string(p[:n]))
}
}
实现自定义的io.Reader
之前我们使用了标准库中的reader,现在我们自己来实现一下Read()接口。
type alphaReader struct {
src string
cur int
}
func newAlphaReader(src string) *alphaReader {
return &alphaReader{src: src}
}
func alpha(r byte) byte {
if (r >= 'A' && r <= 'Z') || (r >= 'a' && r <= 'z') {
return r
}
return 0
}
func (a *alphaReader) Read(p []byte) (int, error) {
if a.cur >= len(a.src) {
return 0, io.EOF
}
x := len(a.src) - a.cur
n, bound := 0, 0
if x >= len(p) {
bound = len(p)
} else if x <= len(p) {
bound = x
}
buf := make([]byte, bound)
for n < bound {
if char := alpha(a.src[a.cur]); char != 0 {
buf[n] = char
}
n++
a.cur++
}
copy(p, buf)
return n, nil
}
func main() {
reader := newAlphaReader("Hello! It's 9am, where is the sun?")
p := make([]byte, 4)
for {
n, err := reader.Read(p)
if err == io.EOF {
break
}
fmt.Print(string(p[:n]))
}
fmt.Println()
}
串联Reader
同字符串Reader串联
很多时候,我们希望可以利用原有的reader而不是全部重写,这时候我们就可以将reader串接起来。
type alphaReader struct {
reader io.Reader
}
func newAlphaReader(reader io.Reader) *alphaReader {
return &alphaReader{reader: reader}
}
func alpha(r byte) byte {
if (r >= 'A' && r <= 'Z') || (r >= 'a' && r <= 'z') {
return r
}
return 0
}
func (a *alphaReader) Read(p []byte) (int, error) {
n, err := a.reader.Read(p)
if err != nil {
return n, err
}
buf := make([]byte, n)
for i := 0; i < n; i++ {
if char := alpha(p[i]); char != 0 {
buf[i] = char
}
}
copy(p, buf)
return n, nil
}
func main() {
// use an io.Reader as source for alphaReader
reader := newAlphaReader(strings.NewReader("Hello! It's 9am, where is the sun?"))
p := make([]byte, 4)
for {
n, err := reader.Read(p)
if err == io.EOF {
break
}
fmt.Print(string(p[:n]))
}
fmt.Println()
}
显然,上面的代码有一个bug,读取源数据之后,如果不是字母会连同目标数据跳过这一位置,这会导致读出来的数据不正确。 聪明的小读者,你能想到该如何解决这个问题吗?
同文件Reader串联
func main() {
// use an os.File as source for alphaReader
file, err := os.Open("./alpha_reader3.go")
if err != nil {
fmt.Println(err)
os.Exit(1)
}
defer file.Close()
reader := newAlphaReader(file)
p := make([]byte, 4)
for {
n, err := reader.Read(p)
if err == io.EOF {
break
}
fmt.Print(string(p[:n]))
}
fmt.Println()
}
io.Writer
接口io.Writer表示一个写入器,将一个缓存中的输入写入到目标。所有的流写入器都需要实现Write(p []byte)接口。
type Writer interface {
Write (p []byte) (n int, err error)
}
返回值是写入了的字节数和错误体。
使用写入器
Go语言预置了很多写入器,我们可以使用bytes.buffer作为一个io.Writer去写入到一段内存中。
func main() {
proverbs := []string{
"Channels orchestrate mutexes serialize",
"Cgo is not Go",
"Errors are values",
"Don't panic",
}
var writer bytes.Buffer
for _, p := range proverbs {
n, err := writer.Write([]byte(p))
if err != nil {
fmt.Println(err)
os.Exit(1)
}
if n != len(p) {
fmt.Println("failed to write data")
os.Exit(1)
}
}
fmt.Println(writer.String())
}
实现一个自定义的io.Writer😉
向channel写入字节
type chanWriter struct {
ch chan byte
}
func newChanWriter() *chanWriter {
return &chanWriter{make(chan byte, 1024)}
}
func (w *chanWriter) Chan() <-chan byte {
return w.ch
}
func (w *chanWriter) Write(p []byte) (int, error) {
n := 0
for _, b := range p {
w.ch <- b
n++
}
return n, nil
}
func (w *chanWriter) Close() error {
close(w.ch)
return nil
}
func main() {
writer := newChanWriter()
go func() {
defer writer.Close()
writer.Write([]byte("Stream "))
writer.Write([]byte("me!"))
}()
for c := range writer.Chan() {
fmt.Printf("%c", c)
}
fmt.Println()
}
通过writer.Write()可以向channel写入字节。
其他的IO库函数
os.File
os.File表示了本地的一个文件,实现了io.Reader和io.Writer两个接口。因此,可以被用在各种需要io的地方。
向文件写入连续的字符串:
func main() {
proverbs := []string{
"Channels orchestrate mutexes serialize\n",
"Cgo is not Go\n",
"Errors are values\n",
"Don't panic\n",
}
file, err := os.Create("./proverbs.txt")
if err != nil {
fmt.Println(err)
os.Exit(1)
}
defer file.Close()
for _, p := range proverbs {
n, err := file.Write([]byte(p))
if err != nil {
fmt.Println(err)
os.Exit(1)
}
if n != len(p) {
fmt.Println("failed to write data")
os.Exit(1)
}
}
fmt.Println("file write done")
}
读取文件:
func main() {
file, err := os.Open("./proverbs.txt")
if err != nil {
fmt.Println(err)
os.Exit(1)
}
defer file.Close()
p := make([]byte, 4)
for {
n, err := file.Read(p)
if err == io.EOF {
break
}
fmt.Print(string(p[:n]))
}
}
标准输入输出错误流
在类unix系统中,都有的os.Stdout,os.Stdin,os.Stderr这三个对象都是*os.File类型,表示了操作系统对应的IO,下面的代码展现了输出到stdout:
func main() {
proverbs := []string{
"Channels orchestrate mutexes serialize\n",
"Cgo is not Go\n",
"Errors are values\n",
"Don't panic\n",
}
for _, p := range proverbs {
n, err := os.Stdout.Write([]byte(p))
if err != nil {
fmt.Println(err)
os.Exit(1)
}
if n != len(p) {
fmt.Println("failed to write data")
os.Exit(1)
}
}
}
io.Copy
io.Copy简化了我们拷贝数据的方式。
func main() {
proverbs := new(bytes.Buffer)
proverbs.WriteString("Channels orchestrate mutexes serialize\n")
proverbs.WriteString("Cgo is not Go\n")
proverbs.WriteString("Errors are values\n")
proverbs.WriteString("Don't panic\n")
file, err := os.Create("./proverbs.txt")
if err != nil {
fmt.Println(err)
os.Exit(1)
}
defer file.Close()
// copy from reader data into writer file
if _, err := io.Copy(file, proverbs); err != nil {
fmt.Println(err)
os.Exit(1)
}
fmt.Println("file created")
}
我们可以简单地重写之前的一段代码:
func main() {
file, err := os.Open("./proverbs.txt")
if err != nil {
fmt.Println(err)
os.Exit(1)
}
defer file.Close()
if _, err := io.Copy(os.Stdout, file); err != nil {
fmt.Println(err)
os.Exit(1)
}
}
io.Copy原理
函数原型如下:
func Copy(dst Writer, src Reader) (written int64, err error) {
return copyBuffer(dst, src, nil)
}
func copyBuffer(dst Writer, src Reader, buf []byte) (written int64, err error) {
....
if buf == nil {
size := 32 * 1024
if l, ok := src.(*LimitedReader); ok && int64(size) > l.N {
if l.N < 1 {
size = 1
} else {
size = int(l.N)
}
}
buf = make([]byte, size)
}
io.Copy32k大小复制源到目标,不会将内容全部读取内,可以解决内存溢出的问题。
copy相关函数
在io包(golang 版本 1.12)中,提供了3个公开的copy方法:CopyN(),Copy(),CopyBuffer().
CopyN(dst,src,n) 为复制src 中 n 个字节到 dst。
Copy(dst,src) 为复制src 全部到 dst 中。
CopyBuffer(dst,src,buf)为指定一个buf缓存区,以这个大小完全复制。
关系如下:
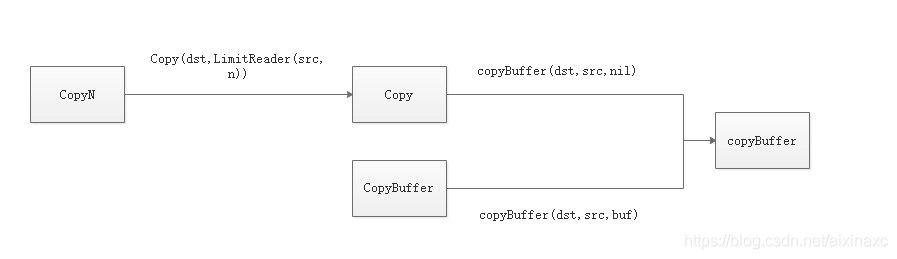
从图可以看出,无论是哪个copy方法最终都是由copyBuffer()这个私有方法实现的。下面我们看看这个方法的源码。
func copyBuffer(dst Writer, src Reader, buf []byte) (written int64, err error) {
// If the reader has a WriteTo method, use it to do the copy.
// Avoids an allocation and a copy.
if wt, ok := src.(WriterTo); ok {
return wt.WriteTo(dst)
}
// Similarly, if the writer has a ReadFrom method, use it to do the copy.
if rt, ok := dst.(ReaderFrom); ok {
return rt.ReadFrom(src)
}
if buf == nil {
size := 32 * 1024
if l, ok := src.(*LimitedReader); ok && int64(size) > l.N {
if l.N < 1 {
size = 1
} else {
size = int(l.N)
}
}
buf = make([]byte, size)
}
for {
nr, er := src.Read(buf)
if nr > 0 {
nw, ew := dst.Write(buf[0:nr])
if nw > 0 {
written += int64(nw)
}
if ew != nil {
err = ew
break
}
if nr != nw {
err = ErrShortWrite
break
}
}
if er != nil {
if er != EOF {
err = er
}
break
}
}
return written, err
}
从这部分代码可以看出,复制主要分为3种。
- 如果被复制的Reader(src)会尝试能否断言成
writerTo,如果可以则直接调用下面的writerTo方法 - 如果
Writer(dst)会尝试能否断言成ReadFrom,如果可以则直接调用下面的readfrom方法 - 如果都木有实现,则调用底层
read实现复制。
其中,有这么一段代码:
if buf == nil {
size := 32 * 1024
if l, ok := src.(*LimitedReader); ok && int64(size) > l.N {
if l.N < 1 {
size = 1
} else {
size = int(l.N)
}
}
buf = make([]byte, size)
}
这部分主要是实现了对Copy和CopyN的处理。通过上面的调用关系图,我们看出CopyN在调用后,会把Reader转成LimitReader。
区别是如果Copy,直接建立一个缓存区默认大小为 32* 1024 的buf,如果是CopyN会先判断 要复制的字节数 如果小于默认大小,会创建一个等于要复制字节数的buf。
io.WriteString()
简化字符串写到一个写入器的方式:
func main() {
file, err := os.Create("./magic_msg.txt")
if err != nil {
fmt.Println(err)
os.Exit(1)
}
defer file.Close()
if _, err := io.WriteString(file, "Go is fun!"); err != nil {
fmt.Println(err)
os.Exit(1)
}
}
管道读写器
类型io.PipeWriter和io.PipeReader是内存中的管道模型,可以从一端写入一端读取。
func main() {
proverbs := new(bytes.Buffer)
proverbs.WriteString("Channels orchestrate mutexes serialize\n")
proverbs.WriteString("Cgo is not Go\n")
proverbs.WriteString("Errors are values\n")
proverbs.WriteString("Don't panic\n")
piper, pipew := io.Pipe()
// write in writer end of pipe
go func() {
defer pipew.Close()
io.Copy(pipew, proverbs)
}()
// read from reader end of pipe.
io.Copy(os.Stdout, piper)
piper.Close()
}
带缓存IO
bufio包支持了带缓存的io,可以更好地配合上下文内容。
func main() {
file, err := os.Open("./planets.txt")
if err != nil {
fmt.Println(err)
os.Exit(1)
}
defer file.Close()
reader := bufio.NewReader(file)
for {
line, err := reader.ReadString('\n')
if err != nil {
if err == io.EOF {
break
} else {
fmt.Println(err)
os.Exit(1)
}
}
fmt.Print(line)
}
}
带缓存的扫描器
bufio.Scanner可以读取我们需要的格式:
const input = `Beware of bugs in the above code;
I have only proved it correct, not tried it.`
scanner := bufio.NewScanner(strings.NewReader(input))
scanner.Split(bufio.ScanWords) // Set up the split function.
count := 0
for scanner.Scan() {
count++
}
if err := scanner.Err(); err != nil {
fmt.Println(err)
}
fmt.Println(count)
ioutil
包ioutil中有一些方便的工具,比如Readfile可以简单地读取文件:
package main
import (
"io/ioutil"
...
)
func main() {
bytes, err := ioutil.ReadFile("./planets.txt")
if err != nil {
fmt.Println(err)
os.Exit(1)
}
fmt.Printf("%s", bytes)
}
参考资料: 1. 参考资料1 2. 参考资料2 3. 参考资料3 4. 参考资料4 5. 参考资料5 6. 参考资料6 7. 参考资料7 8. 参考资料8 9. 参考资料9 10. 参考资料10
1. [参考资料1](https://golang.org/pkg/io/)2. [参考资料2](https://medium.com/learning-the-go-programming-language/streaming-io-in-go-d93507931185)3. [参考资料3](https://yourbasic.org/golang/io-reader-interface-explained/)4. [参考资料4](https://blog.csdn.net/aixinaxc/article/details/88591338)5. [参考资料5](https://www.cnblogs.com/smartrui/p/12110576.html)6. [参考资料6](https://studygolang.com/articles/5187)7. [参考资料7](https://blog.csdn.net/mayifan0/article/details/104043290)8. [参考资料8](https://www.jianshu.com/p/758c4e2b4ab8)9. [参考资料9](https://www.jianshu.com/p/6bda40d003b4)10. [参考资料10](https://blog.csdn.net/u013007900/article/details/89126811)
