
机器学习中不同的距离定义汇总(四:概率分布之间的距离)
- 机器学习中不同的距离定义汇总(四:概率分布之间的距离)
- 皮尔逊相关系数(Pearson Correlation)
- 卡方距离(Chi-square Measure)
- 交叉熵(Cross Entropy)
- 相对熵(Relative Entropy)/ KL散度(Kullback-Leibler Divergence)
- JS散度(Jensen–Shannon Divergence)
- 海林格距离(Hellinger Distance)
- α-散度(α-Divergence)
- F-散度(F-Divergence)
- 布雷格曼散度(Bregman Divergence)
- Wasserstein距离(Wasserstei Distance)/EM距离(Earth-Mover Distance)
- 巴氏距离(Bhattacharyya Distance)
- 最大均值差异(Maximum Mean Discrepancy, MMD)
- 点间互信息(Pointwise Mutual Information, PMI)
- 参考
本文主要参考了此博客和文末列出的参考内容
皮尔逊相关系数(Pearson Correlation)
在统计学中,皮尔逊积矩相关系数(英语:Pearson product-moment correlation coefficient,缩写PPMCC或PCCs)用于度量两个变量X和Y之间的相关程度(线性相关),其值介于-1与1之间。在自然科学领域中,该系数广泛用于度量两个变量之间的线性相关程度。
余弦相似度只与向量方向有关,但它会受到向量的平移影响,在夹角余弦公式中如果将\(x\)平移到\(x + 1\),余弦值就会改变。皮尔逊相关系数(Pearson Correlation)就不会受到这种情况的影响,有时候也皮尔逊相关系数也直接被称为相关系数。
n维空间中的皮尔逊相关系数为:
\[ \rho(x, y)=\frac{\operatorname{cov}(x, y)}{\sigma(x) \cdot \sigma(y)}=\frac{E\left[\left(x-\mu_{x}\right)\left(y-\mu_{y}\right)\right]}{\sigma(x) \cdot \sigma(y)} \]
我们对皮尔逊相关系数做一些简单的变换就可以得到皮尔逊相关系数与余弦相似度之间的关系:
\[ \rho(x, y)=\frac{\operatorname{cov}(x, y)}{\sigma(x) \cdot \sigma(y)}=\frac{\sum_{i=1}^{n}(x-\bar{x})(y-\bar{y})}{|x-\bar{x}| \cdot|y-\bar{y}|}=\cos (x-\bar{x}, y-\bar{y}) \]
python实现:
def PearsonCorrelation(x, y):
import numpy as np
x = np.array(x)
y = np.array(y)
x_ = x-np.mean(x)
y_ = y-np.mean(y)
return np.dot(x_,y_)/(np.linalg.norm(x_)*np.linalg.norm(y_))
卡方距离(Chi-square Measure)
卡方检验经常用来检验某一种观测分布是不是符合某一类典型的理论分布。
观察频数与期望频数越接近,两者之间的差异越小,\(\chi^{2}\)值越小。
如果两个分布完全一致,\(\chi^{2}\)值为0,反之观察频数与期望频数差别越大,两者之间的差异越大,\(\chi^{2}\)值越大。
大的\(\chi^{2}\)值表明观察频数远离期望频数
小的\(\chi^{2}\)值表明观察频数接近期望频数
\(\chi^{2}\)值是观察频数与期望频数之间距离的一种度量指标,也是假设成立与否的度量指标
计算公式如下:
\[ \chi^{2}=\sum_{i=1}^{n} \frac{\left(A_{i}-E_{i}\right)^{2}}{E_{i}}=\sum_{i=1}^{k} \frac{\left(A_{i}-n p_{i}\right)^{2}}{k p_{i}} \]
其中, \(A_{i}\) 为 \(A\) 在水平 \(i\) 的观察频数, \(E_{i}\) 为 \(E\) 在水平 \(i\) 的期望频数, \(k\) 为总频数, \(p_{i}\) 为水平 \(i\) 的期望频率。水平 \(i\) 的期望频数 \(E_{i}\) 等于总频数 \(k \times\) 水平 \(i\) 的期望概率 \(p_{i}\) 。当 \(k\) 比较大时, \(\chi^{2}\) 统计量近似服从 \(n-1\) 个自由度的卡方分布。
python实现:
def ChiSquare(x, y):
import numpy as np
x = np.asarray(x, np.int32)
y = np.asarray(y, np.int32)
return np.sum(np.square(x-y)/y)
交叉熵(Cross Entropy)
交叉熵(Cross Entropy)是香农信息论中一个重要概念,主要用于度量两个概率分布间的差异性信息。交叉熵是表示两个概率分布 \(p, q\), 其中 \(p\) 表示真实分布, \(q\) 表示非真实分布, 则交叉熵用来衡量在给定的真实分布下, 使用 非真实分布所指定的策略消除系统的不确定性所需要付出的努力的大小:
离散值: \(H(p, q)=-\sum_{i=1}^{n} p_{i} \log q_{i}=\sum_{i=1}^{n} p_{i} \log \frac{1}{q_{i}}\)
连续值: \(H(p, q)=E_{p}[\log q]=-\int_{x} p(x) \log q(x) \mathrm{d} x\)
假设现在有一个样本集中两个概率分布 \(p, q\), 其中 \(p\) 表示真实分布, \(q\) 表示非真实分布。假如,按照真实分布 \(p\) 来衡量识别 一个样本所需要的编码长度的期望为:
\[ H(p)=-\sum_{i=1}^{n} p_{i} \log p_{i} \]
但是, 如果采用错误的分布 \(q\) 来表示来自真实分布 \(p\) 的平均编码长度, 则应该是:
\[ H(p, q)=-\sum_{i=1}^{n} p_{i} \log q_{i}=\sum_{i=1}^{n} p_{i} \log \frac{1}{q_{i}} \]
此时就将 \(H(p, q)\) 称之为交叉熵。
python实现:
def CrossEntropy(p, q):
import numpy as np
return -np.sum(p*np.log(q))
相对熵(Relative Entropy)/ KL散度(Kullback-Leibler Divergence)
相对熵(Relative Entropy),又被称为KL散度(Kullback-Leibler Divergence)或信息散度(Information Divergence),是两个概率分布间差异的非对称性度量 。在信息理论中,相对熵等价于两个概率分布的信息熵的差值 。
相对熵也是一些优化算法, 例如最大期望算法的损失函数。此时参与计算的一个概率分布为真实分布, 另一个为非真 实 (拟合) 分布, 相对熵表示使用非真实分布拟合真实分布时产生的信息损耗。设 \(p(x) 、 q(x)\) 是随机变量 \(x\) 上的两个概率分布, 则在离散和连续随机变量的情形下, 相对熵的定义分别为:
离散值: \(\mathrm{KL}(p \| q)=\sum_{x} p(x) \log \frac{p(x)}{q(x)}\)
连续值: \(\mathrm{KL}(p \| q)=\int_{x} p(x) \log \frac{p(x)}{q(x)} \mathrm{d} x\)
在信息理论中, 相对樀是用来度量使用基于 \(q\) 的编码来编码来自 \(p\) 的样本平均所需的额外的比特个数。典型情况下, \(p\) 表示 数据的真实分布, \(q\) 表示数据的理论分布 模型分布或 \(p\) 的近似分布。给定一个字符集的概率分布, 我们可以设计一种编 码, 使得表示该字符集组成的字符吕平均需要的比特数最少。假设这个字符集是 \(X\), 对 \(x \in X\), 其出现概率为 \(p(x)\), 那 么其最优编码平均需要的比特数等于这个字符集的信息熵:
\[H(x)=-\sum_{x} p(x) \log p(x)\]
在同样的字符集上, 假设存在另一个概率分布 \(q(x)\), 如果用概率分布 \(p(x)\) 的最优编码(即字符 \(x\) 的编码长度等于 \(-\log p(x)\) ) , 来为符合分布 \(p(x)\) 的字符编码, 那么表示这些字符就会比理想情况多用一些比特数。相对熵就是用来衡量 这种情况下平均每个字符多用的比特数, 因此可以用来衡量两个分布的距离, 即:
\[ \mathrm{KL}(p \| q)=\sum_{x} p(x) \log \frac{p(x)}{q(x)}=\sum_{x} p(x) \log p(x)-\sum_{x} p(x) \log q(x) \]
python实现:
def RelativeEntropy(p, q):
import numpy as np
p = np.array(p)
q = np.array(q)
return np.sum(p * np.log(p/q))
JS散度(Jensen–Shannon Divergence)
JS散度度量了两个概率分布的相似度,是KL散度的变体,JS散度解决了KL散度非对称的问题。一般地,JS散度是对称的,其取值是0到1之间:
\[ \mathrm{JS}(p, q)=\frac{1}{2} \mathrm{KL}\left(p \| \frac{p+q}{q}\right)+\frac{1}{2} \mathrm{KL}\left(q \| \frac{p+q}{q}\right) \]
python实现:
def JensenShannonDivergence(p, q):
p = np.array(p)
q = np.array(q)
M = (p + q)/2
return 0.5 * np.sum(p*np.log(p/M)) + 0.5 * np.sum(q*np.log(q/M))
海林格距离(Hellinger Distance)
我们假设 \(p\) 和 \(q\) 是两个概率测度, 并且它们对于第三个概率测度 \(\lambda\) 来说是绝对连续的, 则 \(p\) 和 \(q\) 的海林格距离 (Hellinger Distance)的平方被定义如下:
\[ H^{2}(p, q)=\frac{1}{2} \int\left(\sqrt{\frac{\mathrm{d} p}{\mathrm{~d} \lambda}}-\sqrt{\frac{\mathrm{d} q}{\mathrm{~d} \lambda}}\right)^{2} \mathrm{~d} \lambda \]
这里的 \(\frac{\mathrm{d} p}{\mathrm{~d} \lambda}\) 和 \(\frac{\mathrm{d} q}{\mathrm{~d} \lambda}\) 分别是 \(p\) 和 \(q\) 的Radon-Nikodym微分。这里的定义是与 \(\lambda\) 无关的, 因此当我们用另外一个概率测度替换 \(\lambda\) 时, 只要 \(p\) 和 \(q\) 关于它绝对连续, 那么上式就不变。为了简单起见, 我们通常把上式改写为:
\[ H^{2}(p, q)=\frac{1}{2} \int(\sqrt{\mathrm{d} p}-\sqrt{\mathrm{d} q})^{2} \mathrm{~d} \lambda \]
为了在经典的概率论框架下定义Hellinger距离, 我们通常将 \(\lambda\) 定义为Lebesgue度量, 此时 \(\frac{\mathrm{d} p}{\mathrm{~d} \lambda}\) 和 \(\frac{\mathrm{d} q}{\mathrm{~d} \lambda}\) 就变为了我们通常所说 的概率密度函数, 那么可以用以下的积分形式表示Hellinger距离:
\[ H^{2}(p, q)=\frac{1}{2} \int\left(\sqrt{\frac{\mathrm{d} p}{\mathrm{~d} \lambda}}-\sqrt{\frac{\mathrm{d} q}{\mathrm{~d} \lambda}}\right)^{2} \mathrm{~d} \lambda=1-\int \sqrt{\frac{\mathrm{d} p}{\mathrm{~d} \lambda} \frac{\mathrm{d} q}{\mathrm{~d} \lambda}} \mathrm{d} \lambda \]
上述等式可以通过展开平方项得到,注意到任何概率密度函数在其定义域上的积分为1,根据柯西-施瓦茨不等式(Cauchy-Schwarz Inequality),Hellinger距离满足如下性质:
\[ 0 \leq H(p, q) \leq 1 \]
对于两个离散概率分布 \(p=\left(p_{1}, p_{2}, \cdots, p_{n}\right)\) 和 \(q=\left(q_{1}, q_{2}, \cdots, q_{n}\right)\), 它们的Hellinger距离可以定义如下:
\[ H(p, q)=\frac{1}{\sqrt{2}} \sqrt{\sum_{i=1}^{n}\left(\sqrt{p_{i}}-\sqrt{q_{i}}\right)^{2}} \]
上式也可以被看作两个离散概率分布平方根向量的欧几里得距离:
\[ H(p, q)=\frac{1}{\sqrt{2}}\|\sqrt{p}-\sqrt{q}\|_{2} \]
也可以写成:
\[ 1-H^{2}(p, q)=\sum_{i=1}^{n} \sqrt{p_{i} q_{i}} \]
python实现:
def HellingerDistance(p, q):
import numpy as np
p = np.array(p)
q = np.array(q)
M = (p + q)/2
return 1/np.sqrt(2)*np.linalg.norm(np.sqrt(p)-np.sqrt(q))
α-散度(α-Divergence)
α-散度表达式如下:
\[ D_{\alpha}(p \| q)=\frac{4}{1-\alpha^{2}}\left(1-\int p(x)^{\frac{1+\alpha}{2}} q(x)^{\frac{1-\alpha}{2}} \mathrm{~d} x\right) \]
其中, \(-\infty<\alpha<+\infty\) 是一个连续参数。KL散度 \(D_{K L}(p \| q)\) 对应于极限 \(\alpha \rightarrow 1\), 而 \(D_{K L}(q \| p)\) 对应于极限 \(\alpha \rightarrow-1\) 。对于所有的 \(\alpha\) 值, 我们有 \(D_{\alpha}(p \| q) \geq 0\), 当且仅当 \(p(x)=q(x)\) 时等号成立。假设 \(p(x)\) 是一个固定的分布, 我们关于 某个概率分布 \(q(x)\) 的集合最小化 \(D_{\alpha}(p \| q)\) 。那么对于 \(\alpha \leq-1\) 的情况, 散度是零强制的(Zero Forcing), 即对于使得 \(p(x)=0\) 成立的任意 \(X\) 值, 都有 \(q(x)=0\), 通常 \(q(x)\) 会低估 \(p(x)\) 的支持, 因此倾向于寻找具有最大质量的峰值。相 反, 对于 \(\alpha \geq-1\) 的情况, 散度是零避免的(Zero Avoiding), 即对于使得 \(p(x)>0\) 成立的任意 \(X\) 值, 都有 \(q(x)>0\), 通 常 \(q(x)\) 会进行拉伸来覆盖到所有的 \(p(x)\) 值, 从而高估了 \(p(x)\) 的支持。当 \(\alpha=0\) 时, 我们得到了一个对称的散度, 它与 Hellinger距离线性相关:
\[ \left.D_{H}(p \| q)=\int\left(p(x)^{\frac{1}{2}}+q(x)^{\frac{1}{2}}\right) \mathrm{d} x\right) \]
F-散度(F-Divergence)
F-散度(F-Divergence)是KL散度的一个推广:
\[ D_{F}(p \| q)=\int q(x) f\left(\frac{p(x)}{q(x)}\right) \]
其中, 函数 \(f(x)\) 需要满足下列 2 个性质:
- \(f(x)\) 是一个凸函数
- \(f(1)=0\)
若 \(f(x)=x \log x\), 则 \(\mathrm{F}\)-散度退化为 \(\mathrm{KL}\) 散度;若 \(f(x)=-\log x\), 则 \(\mathrm{F}\)-散度退化为reverse KL散度。甚至, 当 \(f(x)\) 取某 些值时, 还可以表达 \(\alpha\)-散度。下面的表格给出了F-散度的一些特例:
| 散度(Divergence) | 对应的 \(f(x)\) |
|---|---|
| KL散度 | \(x \log x\) |
| reverse KL散度 | \(-\log x\) |
| 海林格距离 | \((\sqrt{x}-1)^{2}\) |
| 卡方距离 | \((t-1)^{2}\) |
| α-散度 | \(\frac{4}{1-\alpha^{2}}\left(1-x^{\frac{1+\alpha}{2}}\right) \quad(\alpha \neq \pm 1)\) |
| KL散度 | \(x \log x\) |
python实现:
def f(t):
return t*np.log(t)
def F_Divergence(p, q):
import numpy as np
p = np.array(p)
q = np.array(q)
M = (p + q)/2
return np.sum(q*f(p/q))
布雷格曼散度(Bregman Divergence)
F-散度已经可以表达我们提到的所有散度,目前为止它是最通用的散度形式。但很多文章也会出现另一种叫做Bregman的散度,它和F-散度不太一样,是另一大类散度。
我们以欧几里得距离举例,即n维空间中的欧几里得距离:
\[ d(x, y)=\sqrt{\sum_{i=1}^{n}\left(x_{i}-y_{i}\right)^{2}} \]
我们将其平方:
\[ d^{2}(x, y)=\sum_{i=1}^{n}\left(x_{i}-y_{i}\right)^{2} \]
如果我们定义内积 \(<x, y>=\sum_{i-1}^{n} x_{i} y_{i}\) 和欧式模 \(\|x\|=\sqrt{<x, x>}\), 则上式可以写为如下形式:
\[ d^{2}(x, y)=\sum_{i=1}^{n}\left(x_{i}-y_{i}\right)^{2}=<x-y, x-y>=\|x\|^{2}-\left(\|y\|^{2}+<2 y, x-y>\right) \]
注意到, \(2 y\) 是 \(y^{2}\) 的导数, 因此上式的后一项 \(\left\|y\|^{2}+<2 y, x-y>\right.\) 是函数 \(f(z)=\|z\|^{2}\) 在 \(y\) 点的 切线在 \(x\) 处的取值。所以均方欧几里得距离的几何描述便是欧式模函数在点 \(x\) 和其在 \(y\) 点切线在点估计 的差。如下图绿线所示:
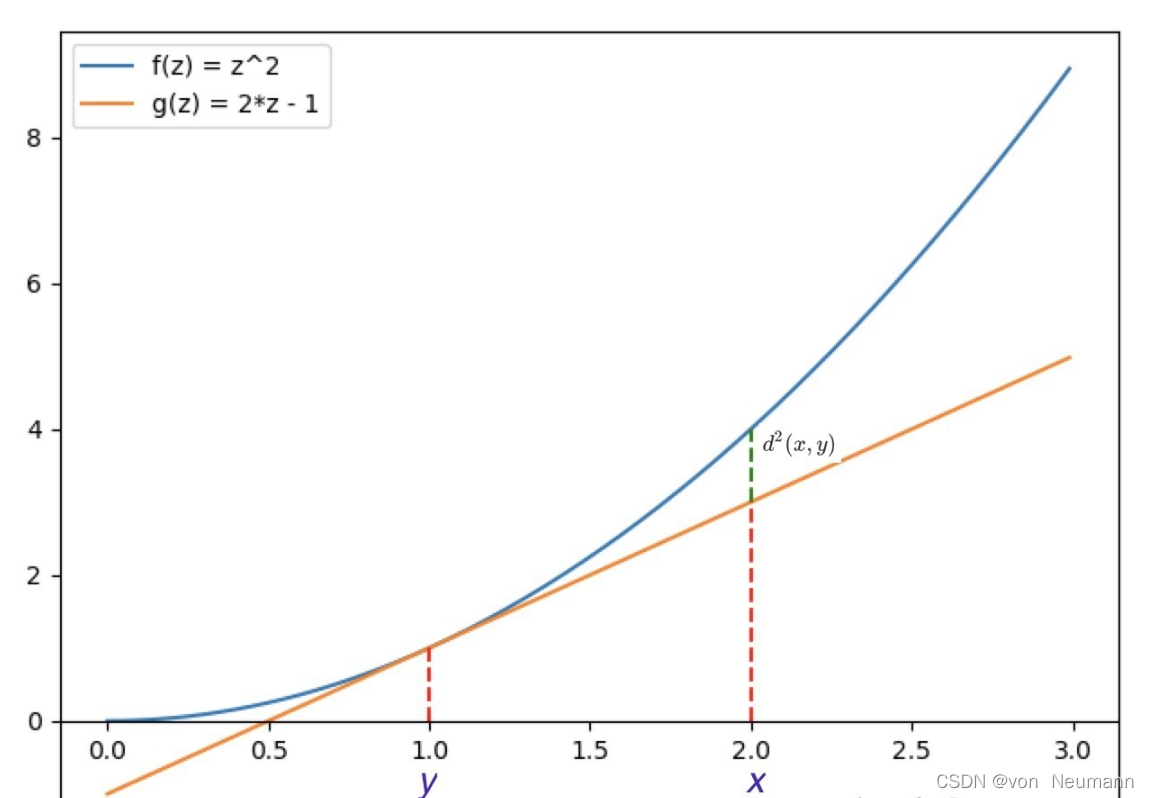
那么一个很自然的想法就是把这个定义拓展, 即对任意 \(R^{n}\) 的函数 \(f(x)\), 我们都可以定义:
\[ d(x, y)=f(x)-(f(y)+<\nabla f(y), x-y>) \]
若 \(f(x)\) 是凸函数, 则可以保证 \(d(x, y) \geq 0\), 上式也是Bregman散度 (Bregman Divergence) 的定义。 和F-散度类似, Bregman散度也是一大类散度的通用表达形式, 具体的, 根据 \(f(x)\) 取不同的函数, 它 可以表示不同的散度, 其中 \(K L\) 散度也是它的一个特例:
\[ \begin{array}{|l|c|c|c|} \hline \text { Domain } & \varphi(\mathbf{x}) & d_{\varphi}(\mathbf{x}, \mathbf{y}) & \text { Divergence } \\ \hline \mathbb{R} & x^{2} & (x-y)^{2} & \text { Squared loss } \\ \hline \mathbb{R}_{+} & x \log x & x \log \left(\frac{x}{y}\right)-(x-y) & \\ \hline[0,1] & x \log x+(1-x) \log (1-x) & x \log \left(\frac{x}{y}\right)+(1-x) \log \left(\frac{1-x}{1-y}\right) & \text { Logistic loss }{ }^{3} \\ \hline \mathbb{R}_{++} & -\log x & \frac{x}{y}-\log \left(\frac{x}{y}\right)-1 & \text { Itakura-Saito distance } \\ \hline \mathbb{R} & e^{x} & e^{x}-e^{y}-(x-y) e^{y} & \\ \hline \mathbb{R}^{d} & \|\mathbf{x}\|^{2} & \|\mathbf{x}-\mathbf{y}\|^{2} & \text { Squared Euclidean distance } \\ \hline \mathbb{R}^{d} & \mathbf{x}^{T} A \mathbf{x} & (\mathbf{x}-\mathbf{y})^{T} A(\mathbf{x}-\mathbf{y}) & \text { Mahalanobis distance } \\ \hline d \text {-Simplex } & \sum_{j=1}^{d} x_{j} \log _{2} x_{j} & \sum_{j=1}^{d} x_{j} \log _{2}\left(\frac{x_{2}}{y_{j}}\right) & \text { KL-divergence } \\ \hline \mathbb{R}_{+}^{d} & \sum_{j=1}^{d} x_{j} \log _{j} & \sum_{j=1}^{d} x_{j} \log \left(\frac{x}{y_{j}}\right)-\sum_{j=1}^{d}\left(x_{j}-y_{j}\right) & \text { Generalized I-sivergence } \\ \hline \end{array} \]
Wasserstein距离(Wasserstei Distance)/EM距离(Earth-Mover Distance)
Wasserstein距离也被称为推土机距离 (Earth Mover’s Distance, EMD), 用来表示两个分布的相似 程度。Wasserstein距离衡量了把数据从分布 \(p\) 移动成”分布 \(q\) 时所需要移动的平均距离的最小值。 Wasserstein距离是2000年IJCV期刊文章《The Earth Mover’s Distance as a Metric for Image Retrieval》提出的一种直方图相似度量。如果两个分布 \(p\) 和 \(q\) 离得很远, 完全没有重叠的时候, 那么 KL散度值是没有意义的, 而JS散度值是一个常数。这在学习算法中是比较致命的, 这就意味这这一点 的梯度为 0 , 即梯度消失, 而Wasserstein距离可以解决这个问题。 我们将两个分布 \(p\) 和 \(q\) 看成两堆土, 如下图所示, 希望把其中的一堆土移成另一堆土的位置和形状, 有 很多种可能的方案。推土代价被定义为移动土的量乘以土移动的距离, 在所有的方案中, 存在一种推 土代价最小的方案, 这个代价就称为两个分布的Wasserstein距离。
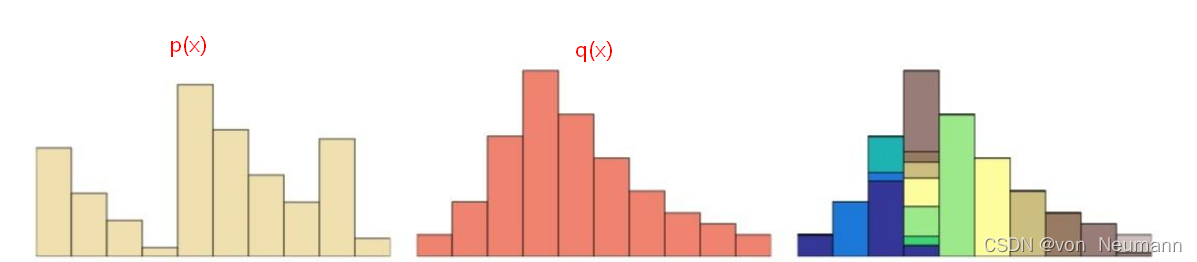
Wasserstein距离的形式化的表达式如下:
\[ W(p, q)=\inf _{\gamma \sim \Pi(p, q)} E_{x, y \sim \gamma}[\|x-y\|] \]
其中, \(\prod(p, q)\) 表示分布 \(p\) 和 \(q\) 组合起来的所有可能的联合分布的集合。对于每一个可能的联合分布 \(\gamma\) 可以从中采样 \((x, y) \sim \gamma\) 得到一个样本 \(x\) 和 \(\mathrm{y}\), 并计算出这对样本的距离 \(\|x-y\|\), 所以可以计算该联 合分布 \(\gamma\) 下, 样本对距离的期望值 \(E_{x, y \sim}[\|x-y\|]\) 。在所有可能的联合分布中能够对这个期望值取 到的下界就是Wasserstein距离。用推土的方式理解就是, \(E_{x, y \sim \gamma}[\|x-y\|]\) 是在 \(\gamma\) 这种路径规划下, 把 \(p\) 这堆土, 移成 \(q\) 的样子的消耗, 而Wasserstein距离就是在”最优路径规划“下的最小消耗。
巴氏距离(Bhattacharyya Distance)
在统计中, 巴氏距离 (Bhattacharyya Distance) 测量两个离散或连续概率分布的相似性。它与衡量 两个统计样品或种群之间的重叠量的巴氏系数密切相关。巴氏距离和巴氏系数以20世纪30年代曾在印 度统计研究所工作的一个统计学家A. Bhattacharya命名。同时, 巴氏系数可以被用来确定两个样本 被认为相对接近的, 它是用来测量中的类分类的可分离性。 首先, 我们先定义离散和连续情况下的巴氏系数:
\[ \begin{aligned} &\text { 离散值: } \quad BC(p, q)=\sum \sqrt{p(x) q(x)} \\ &\text { 连续值: } \quad BC(p, q)=\int \sqrt{p(x) q(x)} \mathrm{d} x \end{aligned} \]
在得到了巴氏系数后巴氏距离被定义为:
\[ D_{B}(p, q)=-\ln (B C(p, q)) \]
从公式可以看出, 巴氏系数 \(B C(p, q)\) 可以海林格距离联系起来, 此时海林格距离可以被定义为:
\[ H(p, q)=\sqrt{1-B C(p, q)} \]
下求 \(B C(p, q)\) 的Python实现以及求出 \(B C(p, q)\) 后求解海林格距离和巴氏距离的 Python实现:
def BC(p,q):
import numpy as np
p = np.array(p)
q = np.array(q)
return np.sum(np.sqrt(p * q))
def HellingerDistance(p, q):
import numpy as np
bc = BC(p,q)
return np.sqrt(1 - bc)
def BhattacharyyaDistance(p, q):
import numpy as np
bc = BC(p,q)
return np.log(bc)
最大均值差异(Maximum Mean Discrepancy, MMD)
最大均值差异 (Maximum Mean Discrepancy, MMD) 是迁移学习, 尤其是域适应 (Domain Adaptation)中使用最广泛的一种损失函数, 主要用来度量两个不同但相关的分布的距离。最大均 值差异还可以用来测试两个样本, 是否来自两个不同分布 \(p\) 和 \(q\), 如果均值差异达到最大, 就说明采样的样本来自完全不同的分布。
最大均值差异度量了在再生 希尔伯特空间中两个分布的距离, 是一种核学习方法。通过寻找在样本 空间上的连续函数 \(f: x \rightarrow R\) 随机投影后, 分别求这两个分布的样本在 \(f\) 上的函数值均值, 并对两个 均值做差得到这两个分布对应于 \(f\) 的均值差 (Mean Discrepancy)。最大均值差异的目标是寻找一个 \(f\) 使得均值差最大, 即得到最大均值差异。
\[ \operatorname{MMD}(F, p, q)=\sup _{\|f\|_{H \leq 1}} E_{p}[f(x)]-E_{q}[f(y)] \]
点间互信息(Pointwise Mutual Information, PMI)
在机器学习实践中, 经常会用到点间互信息 (Pointwise Mutual Information, PMI) 来衡量两个变量的相关性:
\[ \operatorname{PMI}(x, y)=\log \frac{p(x, y)}{p(x) p(y)}=\log \frac{p(x \mid y)}{p(x)}=\log \frac{p(y \mid x)}{p(y)} \]
若 \(x\) 和 \(y\) 不相关, 则 \(p(x, y)=p(x) p(y)\) 。二者相关性越大,则 \(p(x, y)\) 就相比于 \(p(x) p(y)\) 越大。同 理, 在 \(y\) 出现的情况下 \(x\) 出现的条件概率 \(p(x \mid y)\) 除以 \(x\) 本身出现的概率 \(p(x)\), 自然就表示 \(x\) 跟 \(y\) 的相关 程度。
参考
- https://blog.csdn.net/hy592070616/article/details/122277511
- https://zh.wikipedia.org/zh-hans/%E7%9A%AE%E5%B0%94%E9%80%8A%E7%A7%AF%E7%9F%A9%E7%9B%B8%E5%85%B3%E7%B3%BB%E6%95%B0
- https://blog.csdn.net/hy592070616/article/details/122282038
- https://qinqianshan.com/math/distance/chi-square-measure/
- https://blog.csdn.net/hy592070616/article/details/122355256
- https://blog.csdn.net/hy592070616/article/details/122387046
- https://blog.csdn.net/hy592070616/article/details/122394607
- https://blog.csdn.net/hy592070616/article/details/122395719
- https://blog.csdn.net/hy592070616/article/details/122396193
